|
|
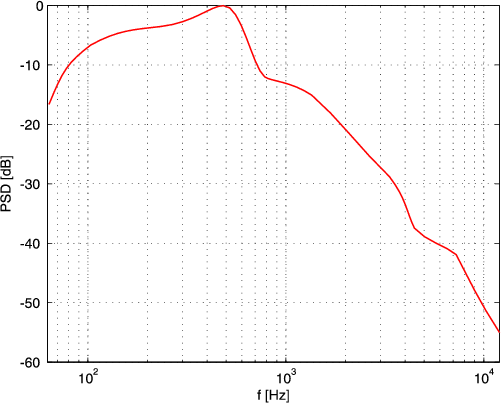
Ispitivanja govornog signala (provedena na većem broju ispitanika) pokazala su da je veći dio snage govora sadržan u nižim frekvencijama, a da razumljivosti više doprinosi viši dio spektra. Na Sl. 1.1. prikazana je spektalna gustoća govornog signala promatrana u dužem vremenskom razdoblju.
Tako je frekvencijsko područje koje se standardno prenosi u telefoniji (300-3400 Hz) posljedica kompromisa kod kojeg se prenosi dovoljna snaga, a razumljivost ostaje zadovoljavajuća. Dinamika govora (razlika volumena glasa najglasnijeg i najtišeg govornika) iznosi oko 62 dB. Kod analogno digitalne–A/D pretvorbe za ovaj raspon amplituda potrebno je 12 bitova/uzorku. Govorni signal sadrži mnogo redundancije. Redundanciju zbog neravnomjerne amplitudne raspodjele koristi standardni PCM sustav (μ i A zakon) i tako reducira potrebnih 12 bitova/uzorku na 8 bitova/uzorku. To uz frekvenciju uzorkovanja od 8 kHz, odnosno 8000 simbola/s daje standarnih 8 ksimbola/s ⋅ 8 bita/uzorku = 64 kbit/sec. Velika korelacija između susjednih uzoraka (do 0.85) koristi se u Diferencijalno impulsno kodiranoj modulaciji – DPCM. Kod DPCM-a, prenosi se razlika susjednih uzoraka, a ne sami uzorci što smanjuje potreban broj bitova po kodnoj riječi za kodiranje. Moguće su uštede od 1 do 2 bita/uzorku u odnosu na standardni PCM signal.
Redundancija, neravnomjerna amplitudna kao i frekvencijska raspodjela su svojstva
karakteristična i za niz drugih signala dok govorni signal ima i neka svojstva tipična
isključivo za govor, a posljedica su samog njegovog mehanizma nastanka. Sa stanovišta
nastanka govorni signal može biti zvučni i bezvučni. Razlika u načinu na koji zvučni i
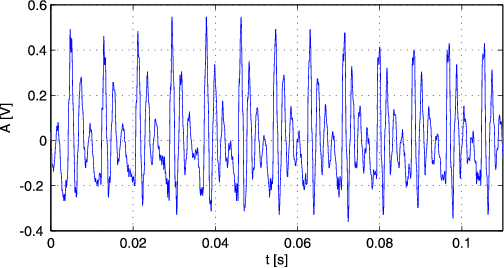
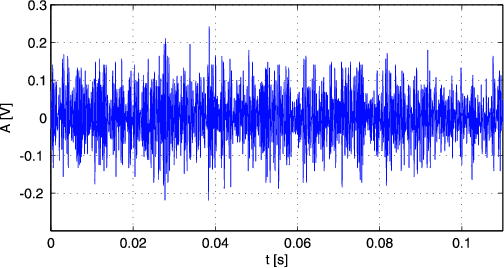
bezvučni glas nastaju očituje se u valnom obliku. Sl. 1.2 prikazuje valni oblik zvu nog
(samoglasnici i kraj nekih suglasnika), a Sl. 1.3 valni oblik bezvučnog (suglasnici) glasa.
Pitch interval, koji karakterizira određenu periodičnost zvučnog glasa, traje 5 do 20 ms kod
muškaraca a 2.5 do 10 ms kod žena (žene dakle imaju kraći pitch period odnosno veću
frekvenciju - "viši glas", a muškarci duži period odnosno manju frekvenciju - "dublji
glas"). Osim toga govor se može promatrati zajedno s mogućnostima ljudskog uha
(slušnog aparata). Tako npr. ljudsko uho ne pravi razliku između faza pojedinih
frekvencija. U suštini, uho je osjetljivo na iznos energije po pojedinoj frekvenciji, a ne na
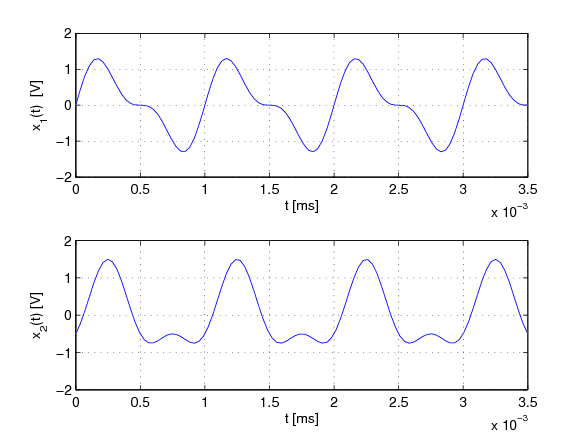
fazni odnos među frekvencijama. Taj efekt prikazan je na Sl. 1.4. Prvi valni oblik
prikazuje dva tona (frekvencije) s istom početnom fazom, a drugi valni oblik iste
tonove ali je jedan ton fazno pomaknut za 90∘
. Iako su valni oblici različiti uho oba
signala čuje jednako. Može se zaključiti da za prijenos govornog signala nije nužno
točno prenositi valni oblik, već trenutni frekvencijski spektar. Ove su karakteristike
govornog signala iskorištene za kodere čija je osnovna značajka da govorni signal ne
kodiraju kao valni oblik već kao niz parametara pa je dekodirani govor sintetički
(umjetni). Jedna od takvih metoda je linearno prediktivno kodiranje – (linear predictive
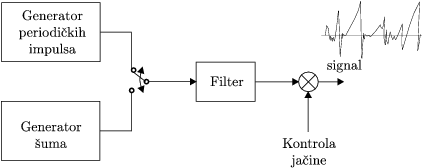
coding LPC) koja koristi model generiranja ljudskog govora prikazan na Sl. 1.5.
nog
(samoglasnici i kraj nekih suglasnika), a Sl. 1.3 valni oblik bezvučnog (suglasnici) glasa.
Pitch interval, koji karakterizira određenu periodičnost zvučnog glasa, traje 5 do 20 ms kod
muškaraca a 2.5 do 10 ms kod žena (žene dakle imaju kraći pitch period odnosno veću
frekvenciju - "viši glas", a muškarci duži period odnosno manju frekvenciju - "dublji
glas"). Osim toga govor se može promatrati zajedno s mogućnostima ljudskog uha
(slušnog aparata). Tako npr. ljudsko uho ne pravi razliku između faza pojedinih
frekvencija. U suštini, uho je osjetljivo na iznos energije po pojedinoj frekvenciji, a ne na
fazni odnos među frekvencijama. Taj efekt prikazan je na Sl. 1.4. Prvi valni oblik
prikazuje dva tona (frekvencije) s istom početnom fazom, a drugi valni oblik iste
tonove ali je jedan ton fazno pomaknut za 90∘
. Iako su valni oblici različiti uho oba
signala čuje jednako. Može se zaključiti da za prijenos govornog signala nije nužno
točno prenositi valni oblik, već trenutni frekvencijski spektar. Ove su karakteristike
govornog signala iskorištene za kodere čija je osnovna značajka da govorni signal ne
kodiraju kao valni oblik već kao niz parametara pa je dekodirani govor sintetički
(umjetni). Jedna od takvih metoda je linearno prediktivno kodiranje – (linear predictive
coding LPC) koja koristi model generiranja ljudskog govora prikazan na Sl. 1.5.
Napomena: 1. Na grafičkom prikazu govornog signala u matlabu na x - osi nalaze se uzorci a ne vrijeme. Vremenski interval između dva uzorka računa se tako da se pomnoži broj uzoraka između dva promatrana uzorka s vremenom između dva susjedna uzorka. Vrijeme između dva susjedna uzorka je recipročna vrijednost frekvencije uzorkovanja koja se može učitati iz filea u kojem je pohranjen audio zapis (vidi funkciju <wavread>, izlazni parametar <fs>).