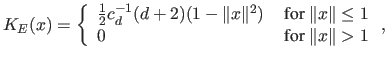Next: Results Up: Fast Two-Step Histogram-Based Image Previous: Grid-based clustering with adaptive
Before describing the details of the algorithm, we comment the selection of
the range domain.
Since the use of the radially symmetric kernel
relies on the Euclidean metric, the implemented color space should satisfy the
assumption that the difference between two colors is proportional to the
length of the straight line joining them. Although the proposed
algorithm is not designed for any particular color space, the performance
could degrade if the assumed Euclidean metric of the color space is not
valid. Further discussion hereafter refers to the algorithm implementation in
approximately uniform ![]() color space.
color space.
The Fast two-step histogram-based image segmentation algorithm (FHS) can be described in following steps:
As the influence of the
Epanechnikov kernel centered at ![]() vanishes for
vanishes for
![]() ,
the contribution of all samples populating the
,
the contribution of all samples populating the ![]() -th cell with center
-th cell with center
![]() is accounted for in the set of cells with center
is accounted for in the set of cells with center ![]() satisfying
satisfying
![]() . The variable bandwidth
. The variable bandwidth ![]() is computed
(8) from the initial estimate
is computed
(8) from the initial estimate
![]() . The
computational complexity of this step is
. The
computational complexity of this step is ![]() , where
, where ![]() is the number
of populated cells and
is the number
of populated cells and
![]() .
.
The region growing mapping procedure is selected to evaluate the ability of
the proposed histogram-based approach to produce quality segmentations. When
implemented as a part of a complex vision system, the
output of the algorithm can be accommodated for a particular application and
the desired input for higher level processing modules. An alternative mapping
procedure (step 6) could be based on the fuzzy region growing [31],
with fuzzy segments which retain uncertainty for propagation to
higher level processing, where more intelligent decisions can be made.
Overall complexity of the FHS algorithm is
![]() .
.
![\includegraphics[width=7.9cm]{IMAGES/EPS-hr08-50.eps}](img90.png) [
[![\includegraphics[width=7.9cm]{IMAGES/EPS-hr12-50.eps}](img91.png)
|
Factor ![]() determines discretization granularity of the color space. This
parameter prescribes the complexity of the density estimation procedure
determines discretization granularity of the color space. This
parameter prescribes the complexity of the density estimation procedure
![]() , as constant
, as constant
![]() directly depends on the average number
of neighboring cells in the discretized domain in which kernel contribution is
accounted for. We fix the discretization granularity to
directly depends on the average number
of neighboring cells in the discretized domain in which kernel contribution is
accounted for. We fix the discretization granularity to ![]() . This
value represents a compromise between the efficiency and the quality of the
provided segmentations. For greater
. This
value represents a compromise between the efficiency and the quality of the
provided segmentations. For greater ![]() space and time complexity of the
algorithm rapidly grows, without prominent advances in the quality of
generated segmentations.
space and time complexity of the
algorithm rapidly grows, without prominent advances in the quality of
generated segmentations.
After fixing parameters
![]() and
and ![]() , the algorithm is driven with
the single parameter
, the algorithm is driven with
the single parameter ![]() which defines the scale of observation in the range
domain. The additional parameter, often used in the segmentation algorithms,
can be the minimum segment size.
which defines the scale of observation in the range
domain. The additional parameter, often used in the segmentation algorithms,
can be the minimum segment size.
Damir Krstinic 2011-11-04